
The d-Separation Criterion in Categorical Probability
Updated: 2023-01-31 16:29:40
Home Page Papers Submissions News Editorial Board Special Issues Open Source Software Proceedings PMLR Transactions TMLR Search Statistics Login Frequently Asked Questions Contact Us The d-Separation Criterion in Categorical Probability Tobias Fritz , Andreas Klingler 24(46 1 49, 2023. Abstract The d-separation criterion detects the compatibility of a joint probability distribution with a directed acyclic graph through certain conditional independences . In this work , we study this problem in the context of categorical probability theory by introducing a categorical definition of causal models , a categorical notion of d-separation , and proving an abstract version of the d-separation criterion . This approach has two main benefits . First , categorical d-separation is a very intuitive
 Harry Enten, pic: CNN Harry Enten (@forecasterenten) is one of the most-high-profile data journalists in the world. He explains the numbers every day on CNN – whether it’s election polling, sports or even his original passion: meterology, specifically snowstorms. “I definitely see myself as a storyteller,” says Enten and he chats with Alberto and Simon about his … Continue reading →
Harry Enten, pic: CNN Harry Enten (@forecasterenten) is one of the most-high-profile data journalists in the world. He explains the numbers every day on CNN – whether it’s election polling, sports or even his original passion: meterology, specifically snowstorms. “I definitely see myself as a storyteller,” says Enten and he chats with Alberto and Simon about his … Continue reading → , Membership Projects Courses Tutorials Newsletter Become a Member Log in Members Only Visualization Tools and Learning Resources , January 2023 Roundup January 26, 2023 Topic The Process roundup Welcome to issue 223 of The Process the newsletter where we look closer at how the charts get made . I’m Nathan Yau , and every month I collect useful tools and resources to help you make better charts . Here’s the good stuff for . January To access this issue of The Process , you must be a . member If you are already a member , log in here Join Now The Process is a weekly newsletter where I evaluate how visualization tools , rules , and guidelines work in practice . I publish every Thursday . Get it in your inbox or access it via the site . You also gain unlimited access to hundreds of hours
, Membership Projects Courses Tutorials Newsletter Become a Member Log in Members Only Visualization Tools and Learning Resources , January 2023 Roundup January 26, 2023 Topic The Process roundup Welcome to issue 223 of The Process the newsletter where we look closer at how the charts get made . I’m Nathan Yau , and every month I collect useful tools and resources to help you make better charts . Here’s the good stuff for . January To access this issue of The Process , you must be a . member If you are already a member , log in here Join Now The Process is a weekly newsletter where I evaluate how visualization tools , rules , and guidelines work in practice . I publish every Thursday . Get it in your inbox or access it via the site . You also gain unlimited access to hundreds of hours Membership Projects Courses Tutorials Newsletter Become a Member Log in Misuse of the rainbow color scheme to visualize scientific data January 26, 2023 Topic Design color nature rainbow science Fabio Crameri , Grace Shephard , and Philip Heron in Nature discuss the drawbacks of using the rainbow color scheme to visualize data and more readable : alternatives The accurate representation of data is essential in science communication . However , colour maps that visually distort data through uneven colour gradients or are unreadable to those with colour-vision deï¬ciency remain prevalent in science . These include , but are not limited to , rainbow-like and redâgreen colour maps . Here , we present a simple guide for the scientiï¬c use of colour . We show how scientiï¬cally derived
Membership Projects Courses Tutorials Newsletter Become a Member Log in Misuse of the rainbow color scheme to visualize scientific data January 26, 2023 Topic Design color nature rainbow science Fabio Crameri , Grace Shephard , and Philip Heron in Nature discuss the drawbacks of using the rainbow color scheme to visualize data and more readable : alternatives The accurate representation of data is essential in science communication . However , colour maps that visually distort data through uneven colour gradients or are unreadable to those with colour-vision deï¬ciency remain prevalent in science . These include , but are not limited to , rainbow-like and redâgreen colour maps . Here , we present a simple guide for the scientiï¬c use of colour . We show how scientiï¬cally derived Membership Projects Courses Tutorials Newsletter Become a Member Log in Cinematic visualization January 25, 2023 Topic Design 3-d cinematic narrative research Using the third dimension in visualization can be tricky because of rendering , perception , and presentation . Matthew Conlen , Jeffrey Heer , Hillary Mushkin , and Scott Davidoff provide a strong use case in their paper on what they call cinematic visualization The many genres of narrative visualization e.g . data comics , data videos each offer a unique set of affordances and constraints . To better understand a genre that we call cinematic visualizationsâ3D visualizations that make highly deliberate use of a camera to convey a narrativeâwe gathered 50 examples and analyzed their traditional cinematic aspects to identify the
Membership Projects Courses Tutorials Newsletter Become a Member Log in Cinematic visualization January 25, 2023 Topic Design 3-d cinematic narrative research Using the third dimension in visualization can be tricky because of rendering , perception , and presentation . Matthew Conlen , Jeffrey Heer , Hillary Mushkin , and Scott Davidoff provide a strong use case in their paper on what they call cinematic visualization The many genres of narrative visualization e.g . data comics , data videos each offer a unique set of affordances and constraints . To better understand a genre that we call cinematic visualizationsâ3D visualizations that make highly deliberate use of a camera to convey a narrativeâwe gathered 50 examples and analyzed their traditional cinematic aspects to identify the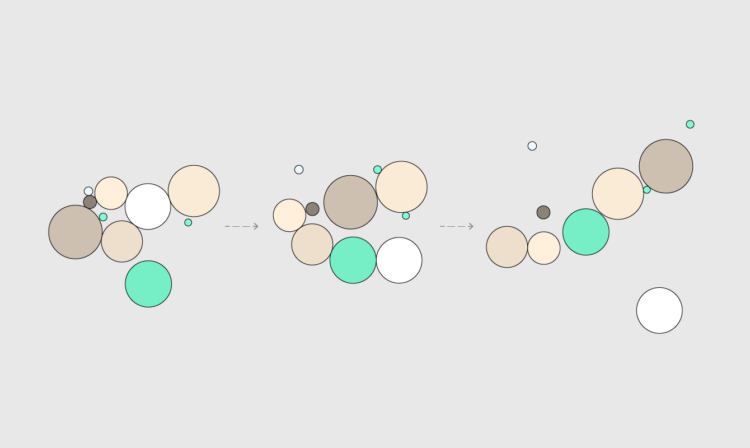 Membership Projects Courses Tutorials Newsletter Become a Member Log in Members Only Tutorials animation R How to Animate Packed Circles in R By Nathan Yau Pack circles , figure out the transitions between time segments , and then generate frames to string . together To animate packed circles , I usually use JavaScript but I’ve been playing with the packcircles package in R . It doesn’t have an animation option , but I was curious how to make things . move To access this full tutorial , you must be a . member If you are already a member , log in here Get instant access to this tutorial and hundreds more , plus courses , guides , and additional . resources Become a Member Membership You will get unlimited access to step-by-step visualization courses and tutorials for insight and
Membership Projects Courses Tutorials Newsletter Become a Member Log in Members Only Tutorials animation R How to Animate Packed Circles in R By Nathan Yau Pack circles , figure out the transitions between time segments , and then generate frames to string . together To animate packed circles , I usually use JavaScript but I’ve been playing with the packcircles package in R . It doesn’t have an animation option , but I was curious how to make things . move To access this full tutorial , you must be a . member If you are already a member , log in here Get instant access to this tutorial and hundreds more , plus courses , guides , and additional . resources Become a Member Membership You will get unlimited access to step-by-step visualization courses and tutorials for insight and